제로베이스 데이터 파트타임 스쿨 학습 일지 [25.04.20]
[강의 요약]
[Part 03. 자료구조&알고리즘 with Python_ Ch 01. 자료구조] 강의 수강
05_리스트와 for문(01)부터 09_enumerate()함수까지 강의 수강하였음
🐢 100일 챌린지 🔥 : [▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰░ ] 35/100일 (35%)벌써 2025년 4월의 절반이 지나간다.
남은 시간 더 알차게 써야지
[05_리스트와 for문 (01)]
▶ 리스트를 for문으로 출력하는 방법
1. 인덱스 기반 접근
cars = ['그랜저', '소나타', '말리부', '카니발', '쏘렌토']
for i in range(len(cars)):
print(cars[i])[출력 결과]
그랜저
소나타
말리부
카니발
쏘렌토
2. 직접 아이템 참조 (for-each 방식)
for car in cars:
print(car)[출력 결과]
그랜저
소나타
말리부
카니발
쏘렌토
▶ 이중 리스트 순회하기
studentCnts = [[1, 19], [2, 20], [3, 22], [4, 18], [5, 21]]1. 인덱스로 접근
for i in range(len(studentCnts)):
print('{}학급 학생수: {} '.format(studentCnts[i][0], studentCnts[i][1]))
2. 변수 분리로 접근
for classNo, cnt in studentCnts:
print('{}학급 학생수: {}'.format(classNo, cnt))[출력 결과]
1, 2 출력 결과는 동일하다.
1학급 학생수: 19
2학급 학생수: 20
3학급 학생수: 22
4학급 학생수: 18
5학급 학생수: 21
▶ 코드 : 전체 학생 수와 평균 구하기
studentCnts = [[1, 18], [2, 19], [3, 23], [4, 21], [5, 20], [6, 22], [7, 17]]
sum = 0
for classNo, cnt in studentCnts:
print('{}학급 학생수: {}명'.format(classNo, cnt))
sum += cnt
print('전체 학생 수: {}명'.format(sum))
print('평균 학생 수: {}명'.format(sum / len(studentCnts)))[출력 결과]
1학급 학생수: 18명
2학급 학생수: 19명
3학급 학생수: 23명
4학급 학생수: 21명
5학급 학생수: 20명
6학급 학생수: 22명
7학급 학생수: 17명
전체 학생 수: 140명
평균 학생 수: 20.0명
[06_리스트와 for문 (02)]
▶ 코드 : 과락 과목 출력 (기준 점수 60점 미만)
minScore = 60
scores = [
['국어', 58],
['영어', 77],
['수학', 89],
['과학', 99],
['국사', 50]
]
for item in scores:
if item[1] < minScore:
print('과락 과목: {}, 점수: {}'.format(item[0], item[1]))
(언팩킹 방식으로도 가능함)
for subject, score in scores:
if score < minScore:
print('과락 과목: {}, 점수: {}'.format(subject, score))
(continue를 활용한 필터링)
for subject, score in scores:
if score >= minScore: continue
print('과락 과목: {}, 점수: {}'.format(subject, score))[출력 결과]
과락 과목: 국어, 점수: 58
과락 과목: 국사, 점수: 50
▶ 코드 : 사용자 입력 기반 과락 판단
minScore = 60
korScore = int(input('국어 점수: '))
engScore = int(input('영어 점수: '))
matScore = int(input('수학 점수: '))
sciScore = int(input('과학 점수: '))
hisScore = int(input('국사 점수: '))
scores = [
['국어', korScore],
['영어', engScore],
['수학', matScore],
['과학', sciScore],
['국사', hisScore]
]
for subject, score in scores:
if score < minScore:
print('과락 과목: {}, 점수: {}'.format(subject, score))[입력 / 출력]
국어 점수: 50
영어 점수: 70
수학 점수: 85
과학 점수: 40
국사 점수: 90
과락 과목: 국어, 점수: 50
과락 과목: 과학, 점수: 40
▶ 코드 : 가장 작은 학급 & 가장 많은 학급 찾기
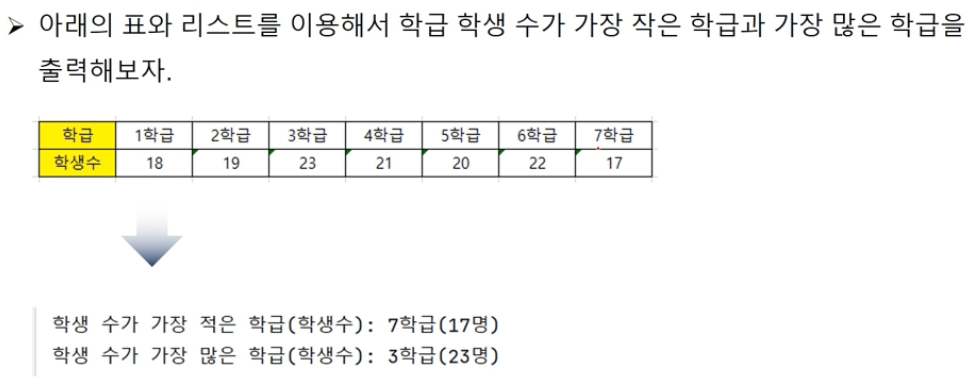
studentCnts = [[1, 18], [2, 19], [3, 23], [4, 21], [5, 20], [6, 22], [7, 17]]
minclassNo = 0
maxclassNo = 0
minCnt = 0
maxCnt = 0
for classNo, cnt in studentCnts:
if minCnt == 0 or minCnt > cnt:
minclassNo = classNo
minCnt = cnt
if maxCnt < cnt:
maxclassNo = classNo
maxCnt = cnt
print('학생 수가 가장 적은 학급(학생수): {}학급({}명)'.format(minclassNo, minCnt))
print('학생 수가 가장 많은 학급(학생수): {}학급({}명)'.format(maxclassNo, maxCnt))[출력 결과]
학생 수가 가장 적은 학급(학생수): 7학급(17명)
학생 수가 가장 많은 학급(학생수): 3학급(23명)
[07_리스트와 while문 (01)]
▶ while문이란?
조건이 True인 동안 계속 반복 실행되는 반복문임
리스트의 길이와 인덱스를 조합해 순차적으로 항목을 접근할 수 있음
▶ 코드 : 리스트를 while문으로 출력
cars = ['그랜저', '소나타', '말리부', '카니발', '쏘렌토']
n = 0
while n < len(cars):
print(cars[n])
n += 1[출력 결과]
그랜저
소나타
말리부
카니발
쏘렌토
▶ 다른 방식으로 종료조건 설정하는 방법
동일한 결과를 출력하지만, 알아두면 상황에 따라 유용하게 선택 가능함
1. flag 변수로 제어
n = 0
flag = True
while flag:
print(cars[n])
n += 1
if n == len(cars):
flag = False
2. break문을 이용한 무한루프 탈출
n = 0
while True:
print(cars[n])
n += 1
if n == len(cars):
break
▶ 코드 : 이중 리스트 순회 – 학급별 학생 수 출력
studentCnts = [[1, 19], [2, 20], [3, 22], [4, 18], [5, 21]]
n = 0
while n < len(studentCnts):
print('{}학급 학생수: {} '.format(studentCnts[n][0], studentCnts[n][1]))
n += 1[출력 결과]
1학급 학생수: 19
2학급 학생수: 20
3학급 학생수: 22
4학급 학생수: 18
5학급 학생수: 21
▶ 코드 : 전체 학생 수와 평균 구하기

studentCnts = [[1, 18], [2, 19], [3, 23], [4, 21], [5, 20], [6, 22], [7, 17]]
sum = 0
n = 0
while n < len(studentCnts):
classNo = studentCnts[n][0]
cnt = studentCnts[n][1]
print('{}학급 학생수: {}명'.format(classNo, cnt))
sum += cnt
n += 1
print('전체 학생 수: {}명'.format(sum))
print('평균 학생 수: {}명'.format(sum / len(studentCnts)))[출력 결과]
1학급 학생수: 18명
2학급 학생수: 19명
3학급 학생수: 23명
4학급 학생수: 21명
5학급 학생수: 20명
6학급 학생수: 22명
7학급 학생수: 17명
전체 학생 수: 140명
평균 학생 수: 20.0명
[08_리스트와 while문 (02)]
▶ 코드 : 과락 과목 출력 (기준 점수 60점 미만)
minScore = 60
scores = [
['국어', 58],
['영어', 77],
['수학', 89],
['과학', 99],
['국사', 50]
]
n = 0
while n < len(scores):
if scores[n][1] < minScore:
print('과락 과목: {}, 점수: {}'.format(scores[n][0], scores[n][1]))
n += 1[출력 결과]
과락 과목: 국어, 점수: 58
과락 과목: 국사, 점수: 50
※ continue를 활용한 패턴
n = 0
while n < len(scores):
if scores[n][1] >= minScore:
n += 1
continue
print('과락 과목: {}, 점수: {}'.format(scores[n][0], scores[n][1]))
n += 1
▶ 코드 : 사용자 입력 기반 과락 판단

minScore = 60
korScore = int(input('국어 점수: '))
engScore = int(input('영어 점수: '))
matScore = int(input('수학 점수: '))
sciScore = int(input('과학 점수: '))
hisScore = int(input('국사 점수: '))
scores = [
['국어', korScore],
['영어', engScore],
['수학', matScore],
['과학', sciScore],
['국사', hisScore]
]
n = 0
while n < len(scores):
if scores[n][1] < minScore:
print('과락 과목: {}, 점수: {}'.format(scores[n][0], scores[n][1]))
n += 1[입력 / 출력]
국어 점수: 50
영어 점수: 70
수학 점수: 85
과학 점수: 40
국사 점수: 90
과락 과목: 국어, 점수: 50
과락 과목: 과학, 점수: 40
▶ 코드 : 학생 수 최솟값 & 최댓값 학급 찾기
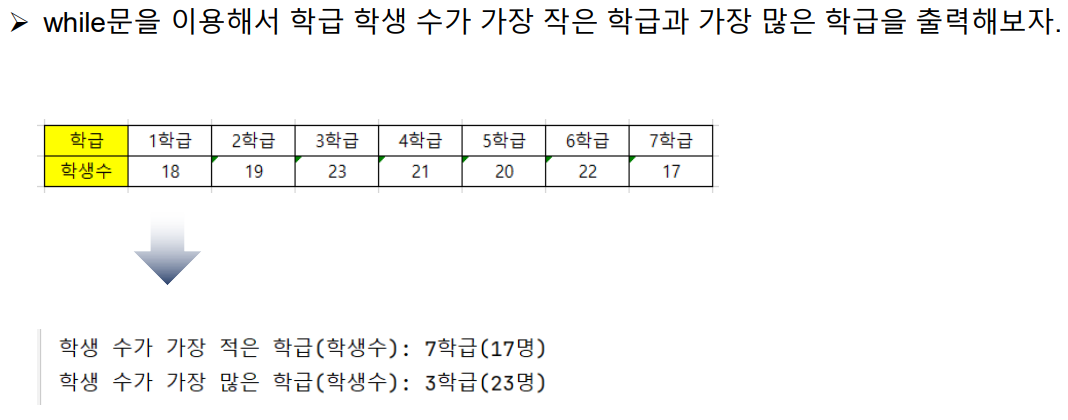
studentCnts = [[1, 18], [2, 19], [3, 23], [4, 21], [5, 20], [6, 22], [7, 17]]
minclassNo = 0
maxclassNo = 0
minCnt = 0
maxCnt = 0
n = 0
while n < len(studentCnts):
if minCnt == 0 or minCnt > studentCnts[n][1]:
minclassNo = studentCnts[n][0]
minCnt = studentCnts[n][1]
if maxCnt < studentCnts[n][1]:
maxclassNo = studentCnts[n][0]
maxCnt = studentCnts[n][1]
n += 1
print('학생 수가 가장 적은 학급(학생수): {}학급({}명)'.format(minclassNo, minCnt))
print('학생 수가 가장 많은 학급(학생수): {}학급({}명)'.format(maxclassNo, maxCnt))[출력 결과]
학생 수가 가장 적은 학급(학생수): 7학급(17명)
학생 수가 가장 많은 학급(학생수): 3학급(23명)
[09_enumerate()함수]
▶ enumerate() 함수란?
반복 가능한 객체를 인덱스와 함께 반환해 주는 함수
반복문에서 인덱스를 따로 관리하지 않아도 되는 게 특징
for index, value in enumerate(리스트):
...문자열에도 사용 가능함 : enumerate("Hello")
▶ 코드 : 리스트 인덱스 출력 – 기존 방식 vs enumerate 비교
1. 일반 for문 (range + 인덱스)
sports = ['농구', '수구', '축구', '마라톤', '테니스']
for i in range(len(sports)):
print('{} : {}'.format(i, sports[i]))
2. enumerate 사용
for idx, value in enumerate(sports):
print('{} : {}'.format(idx, value))[출력 결과]
출력 결과는 동일함
0 : 농구
1 : 수구
2 : 축구
3 : 마라톤
4 : 테니스
▶ 코드 : 문자열에 enumerate 사용
str = 'Hello python.'
for idx, value in enumerate(str):
print('{} : {}'.format(idx, value))[출력 결과]
0 : H
1 : e
2 : l
3 : l
4 : o
...문자열도 하나하나의 문자로 분리되어 인덱스와 함께 출력됨
▶ 코드 : 좋아하는 스포츠의 위치 찾기

sports = ['농구', '수구', '축구', '마라톤', '테니스']
favoriteSport = input('가장 좋아하는 스포츠 입력: ')
bestSportIdx = 0
for idx, value in enumerate(sports):
if value == favoriteSport:
bestSportIdx = idx + 1 # 사람 기준 번호
print('{}(은)는 {}번째에 있습니다.'.format(favoriteSport, bestSportIdx))[입력 / 출력]
가장 좋아하는 스포츠 입력: 축구
축구(은)는 3번째에 있습니다.
▶ 코드 : 공백 개수 세기
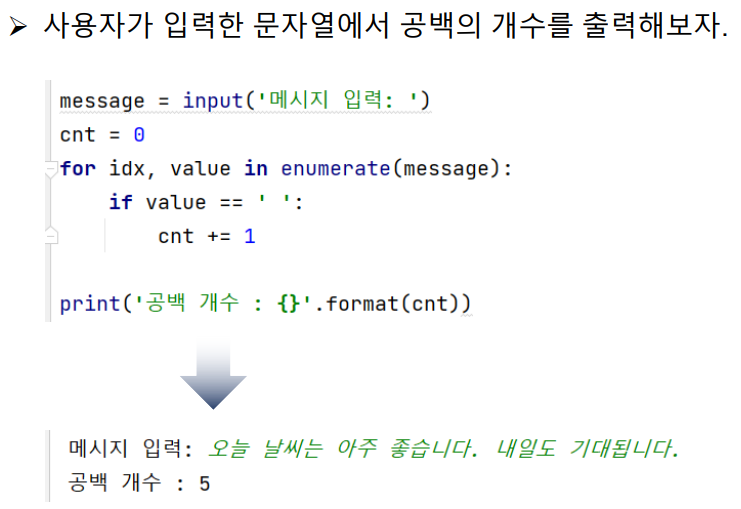
message = input('메시지 입력: ')
cnt = 0
for idx, value in enumerate(message):
if value == ' ':
cnt += 1
print('공백 개수 : {}'.format(cnt))[입력 / 출력]
메시지 입력: Hello my friend.
공백 개수 : 2
[나의 생각 정리]
최근 백준 브론즈 문제들을 단계별로 풀고 있는데, 리스트를 활용해야 하는 경우가 정말 많다는 걸 느낀다.
이렇게 블로그에 글로 정리하면서 공부하면 이해도 더 잘되고
나중에 기억이 잘 안 나거나 막힐 때 다시 찾아보기에도 아주 유용한 것 같다.
[적용점]
백준 브론즈~실버 문제에 당장 적용해서 풀 수 있다.
“이 글은 제로베이스 데이터 스쿨 주 3일반 강의 자료 일부를 발췌하여 작성되었습니다.”