제로베이스 데이터 파트타임 스쿨 학습 일지 [25.04.26]
[강의 요약]
[Part 03. 자료구조&알고리즘 with Python_ Ch 01. 자료구조] 강의 수강
35_딕셔너리 수정부터 38_딕셔너리 유용한 기능까지 강의 수강하였음
🐢 100일 챌린지 🔥 : [▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰░ ] 41/100일 (41%)오늘 자격증 시험... 시간이 많이 부족했다 ㅠㅠ
[35_딕셔너리 수정]
▶ 딕셔너리 값은 어떻게 수정할까?
dict[key] = 새로운 값 형태로 간단하게 수정
하지만 없는 key라면 '추가'처럼 새로 삽입됨
조건문이나 반복문을 활용하여 대량 수정 가능함
▶ 코드 : 기본 딕셔너리 수정
myInfo = {}
myInfo['이름'] = '박경진'
myInfo['전공'] = 'computer'
myInfo['메일'] = 'jin@naver.com'
myInfo['학년'] = 3
myInfo['주소'] = '대한민국 서울'
myInfo['취미'] = ['요리', '여행']
print(f'myInfo : {myInfo}')
# 값 수정
myInfo['전공'] = 'sports'
myInfo['학년'] = '4'
print(f'myInfo : {myInfo}')[출력 결과]
myInfo : {'이름': '박경진', '전공': 'computer', '메일': 'jin@naver.com', '학년': 3, '주소': '대한민국 서울', '취미': ['요리', '여행']}
myInfo : {'이름': '박경진', '전공': 'sports', '메일': 'jin@naver.com', '학년': '4', '주소': '대한민국 서울', '취미': ['요리', '여행']}
▶ 실습 코드 : 점수가 60점 미만이면 'F(재시험)'으로 변경
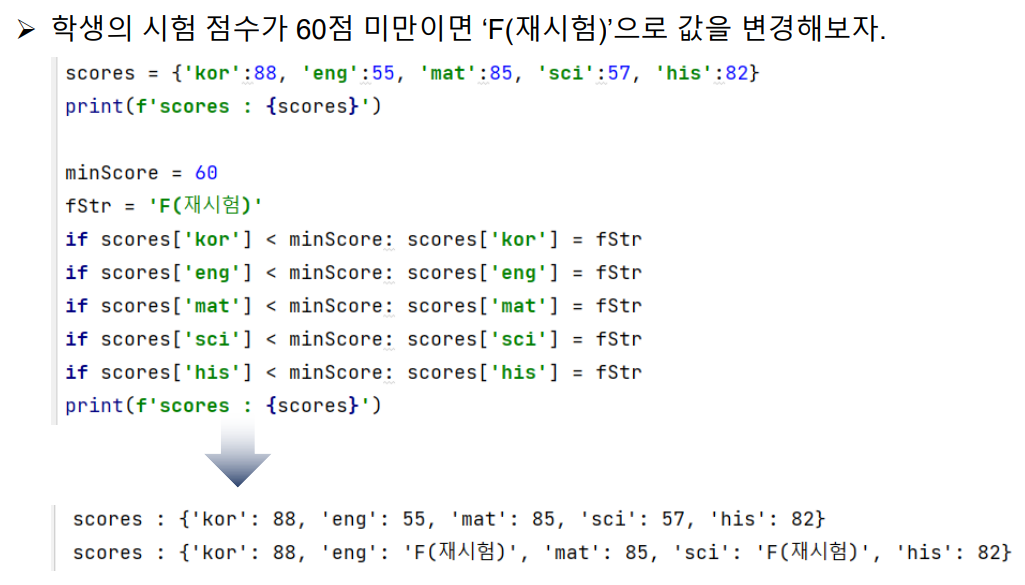
scores = {'kor':88, 'eng':55, 'mat':85, 'sci':57, 'his':82}
print(f'scores : {scores}')
minScore = 60
fStr = 'F(재시험)'
if scores['kor'] < minScore: scores['kor'] = fStr
if scores['eng'] < minScore: scores['eng'] = fStr
if scores['mat'] < minScore: scores['mat'] = fStr
if scores['sci'] < minScore: scores['sci'] = fStr
if scores['his'] < minScore: scores['his'] = fStr
print(f'scores : {scores}')[출력 결과]
scores : {'kor': 88, 'eng': 55, 'mat': 85, 'sci': 57, 'his': 82}
scores : {'kor': 88, 'eng': 'F(재시험)', 'mat': 85, 'sci': 'F(재시험)', 'his': 82}
▶ 실습 코드 : 몸무게, 신장 변화 및 BMI 계산

myBodyInfo = {'이름':'gildong', '몸무게':83.0, '신장':1.8}
myBMI = myBodyInfo['몸무게'] / (myBodyInfo['신장'] ** 2)
print(f'myBodyInfo: {myBodyInfo}')
print(f'myBMI: {round(myBMI, 2)}')
date = 0
while True:
date += 1
myBodyInfo['몸무게'] = round((myBodyInfo['몸무게'] - 0.3), 2)
print('몸무게: ', myBodyInfo['몸무게'])
myBodyInfo['신장'] = round((myBodyInfo['신장'] + 0.001), 3)
print('신장: ', myBodyInfo['신장'])
myBMI = myBodyInfo['몸무게'] / (myBodyInfo['신장'] ** 2)
if date >= 30:
break
print(f'myBodyInfo: {myBodyInfo}')
print(f'myBMI: {round(myBMI, 2)}')[출력 결과]
myBodyInfo: {'이름': 'gildong', '몸무게': 83.0, '신장': 1.8}
myBMI: 25.62
몸무게: 82.7
신장: 1.801
...
몸무게: 74.0
신장: 1.83
myBodyInfo: {'이름': 'gildong', '몸무게': 74.0, '신장': 1.83}
myBMI: 22.09
[36_key()와 values()]
▶ 기본 사용법 정리
- dict.key()
- 모든 key를 반환
- dict.values()
- 모든 value를 반환
- dict.items()
- (key, value) 쌍을 반환
- list()
- 반환된 결과를 리스트로 변환 가능
▶ 코드 : keys(), values(), items() 사용 및 리스트 변환
memInfo = {'이름':'홍길동', '메일':'gildong@gmail.com', '학년':3, '취미':['농구', '게임']}
ks = memInfo.keys()
print(f'ks : {ks}')
print(f'ks type : {type(ks)}')
vs = memInfo.values()
print(f'vs : {vs}')
print(f'vs type : {type(vs)}')
items = memInfo.items()
print(f'items : {items}')
print(f'items type : {type(items)}')
# 리스트로 변환
ks = list(ks)
vs = list(vs)
items = list(items)
print(f'ks : {ks}')
print(f'vs : {vs}')
print(f'items : {items}')[출력 결과]
ks : dict_keys(['이름', '메일', '학년', '취미'])
ks type : <class 'dict_keys'>
vs : dict_values(['홍길동', 'gildong@gmail.com', 3, ['농구', '게임']])
vs type : <class 'dict_values'>
items : dict_items([('이름', '홍길동'), ('메일', 'gildong@gmail.com'), ('학년', 3), ('취미', ['농구', '게임'])])
items type : <class 'dict_items'>
ks : ['이름', '메일', '학년', '취미']
vs : ['홍길동', 'gildong@gmail.com', 3, ['농구', '게임']]
items : [('이름', '홍길동'), ('메일', 'gildong@gmail.com'), ('학년', 3), ('취미', ['농구', '게임'])]
▶ 코드 : 리스트로 변환 후 인덱싱
print(f'ks[0] : {ks[0]}')
print(f'vs[0] : {vs[0]}')
print(f'items[0] : {items[0]}')[출력 결과]
ks[0] : 이름
vs[0] : 홍길동
items[0] : ('이름', '홍길동')
▶ 코드 : for문으로 조회
for key in ks:
print(f'key: {key}')
for idx, key in enumerate(ks):
print(f'idx, key: {idx}, {key}')
for value in vs:
print(f'value: {value}')
for idx, value in enumerate(vs):
print(f'idx, value: {idx}, {value}')
for item in items:
print(f'item: {item}')
for idx, item in enumerate(items):
print(f'idx, item: {idx}, {item}')
for key in memInfo.keys():
print(f'{key}: {memInfo[key]}')[출력 결과]
key: 이름
key: 메일
key: 학년
key: 취미
...
idx, key: 0, 이름
idx, key: 1, 메일
...
value: 홍길동
value: gildong@gmail.com
...
item: ('이름', '홍길동')
item: ('메일', 'gildong@gmail.com')
...
이름: 홍길동
메일: gildong@gmail.com
...
▶ 실습 코드 : 점수 60점 미만 과목만 'F(재시험)' 처리하기

scores = {'kor':88, 'eng':55, 'mat':85, 'sci':57, 'his':82}
print(f'scores: {scores}')
minScore = 60
fStr = 'F(재시험)'
fDic = {}
for key in scores:
if scores[key] < minScore:
scores[key] = fStr
fDic[key] = fStr
print(f'scores: {scores}')
print(f'fDic: {fDic}')[출력 결과]
scores: {'kor': 88, 'eng': 55, 'mat': 85, 'sci': 57, 'his': 82}
scores: {'kor': 88, 'eng': 'F(재시험)', 'mat': 85, 'sci': 'F(재시험)', 'his': 82}
fDic: {'eng': 'F(재시험)', 'sci': 'F(재시험)'}
[37_딕셔너리 삭제]
▶ 기본 사용법 정리
- del dict[key]
- 해당 ket-value를 삭제. 삭제한 값 변환 없음
- dict.pop(key)
- 해당 key-value를 삭제하고, 삭제한 값을 변환
▶ 코드 : del을 사용한 삭제
memInfo = {'이름':'홍길동', '메일':'gildong@gmail.com', '학년':3, '취미':['농구', '게임']}
print(f'memInfo: {memInfo}')
del memInfo['메일']
print(f'memInfo: {memInfo}')
del memInfo['취미']
print(f'memInfo: {memInfo}')[출력 결과]
memInfo: {'이름': '홍길동', '메일': 'gildong@gmail.com', '학년': 3, '취미': ['농구', '게임']}
memInfo: {'이름': '홍길동', '학년': 3, '취미': ['농구', '게임']}
memInfo: {'이름': '홍길동', '학년': 3}
▶ 코드 : pop()을 사용한 삭제 및 반환값 확인
memInfo = {'이름':'홍길동', '메일':'gildong@gmail.com', '학년':3, '취미':['농구', '게임']}
print(f'memInfo: {memInfo}')
returnValue = memInfo.pop('이름')
print(f'memInfo: {memInfo}')
print(f'returnValue: {returnValue}')
print(f'returnValue type: {type(returnValue)}')
returnValue = memInfo.pop('취미')
print(f'memInfo: {memInfo}')
print(f'returnValue: {returnValue}')
print(f'returnValue type: {type(returnValue)}')[출력 결과]
memInfo: {'이름': '홍길동', '메일': 'gildong@gmail.com', '학년': 3, '취미': ['농구', '게임']}
memInfo: {'메일': 'gildong@gmail.com', '학년': 3, '취미': ['농구', '게임']}
returnValue: 홍길동
returnValue type: <class 'str'>
memInfo: {'메일': 'gildong@gmail.com', '학년': 3}
returnValue: ['농구', '게임']
returnValue type: <class 'list'>
▶ 실습 코드 : 점수에서 최저점과 최고점을 찾아 삭제
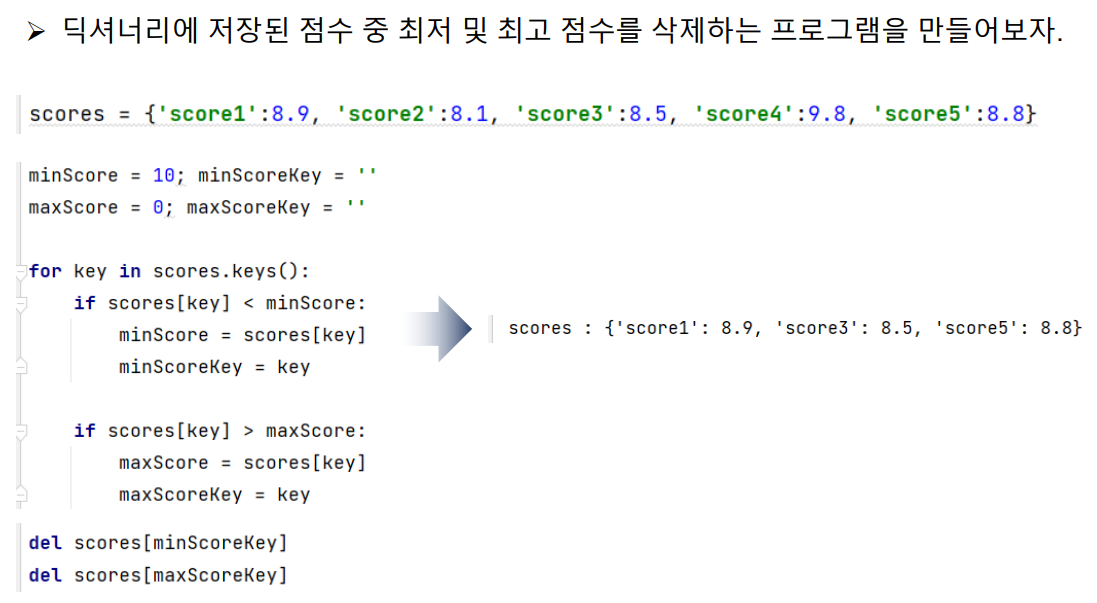
scores = {'score1':8.9, 'score2':8.1, 'score3':8.5, 'score4':9.8, 'score5':8.8}
minScore = 10
minScoreKey = ''
maxScore = 0
maxScoreKey = ''
for key in scores.keys():
if scores[key] < minScore:
minScore = scores[key]
minScoreKey = key
if scores[key] > maxScore:
maxScore = scores[key]
maxScoreKey = key
print('minScore : {}'.format(minScore))
print('minScoreKey : {}'.format(minScoreKey))
print('maxScore : {}'.format(maxScore))
print('maxScoreKey : {}'.format(maxScoreKey))
del scores[minScoreKey]
del scores[maxScoreKey]
print('scores : {}'.format(scores))[출력 결과]
minScore : 8.1
minScoreKey : score2
maxScore : 9.8
maxScoreKey : score4
scores : {'score1': 8.9, 'score3': 8.5, 'score5': 8.8}
[38_딕셔너리 유용한 기능]
▶ 기본 사용법 정리
- in, not in
- 딕셔너리에서 "키" 존재 여부 확인
- len(dictionary)
- 딕셔너리의 항목 수 반환
- clear()
- 딕셔너리 비우기
▶ 코드 : in, not in 사용
memInfo = {'이름':'홍길동', '메일':'gildong@gmail.com', '학년':3, '취미':['농구', '게임']}
print('이름' in memInfo)
print('메일' in memInfo)
print('학년' in memInfo)
print('취미' in memInfo)
print('name' not in memInfo)
print('mail' not in memInfo)
print('grade' not in memInfo)
print('hobby' not in memInfo)[출력 결과]
True
True
True
True
True
True
True
True
▶ 코드 : len()과 clear() 사용
print('len(memInfo) : {}'.format(len(memInfo)))
print('memInfo: {}'.format(memInfo))
memInfo.clear()
print('memInfo: {}'.format(memInfo))[출력 결과]
len(memInfo) : 4
memInfo: {'이름': '홍길동', '메일': 'gildong@gmail.com', '학년': 3, '취미': ['농구', '게임']}
memInfo: {}
▶ 실습 코드 : 개인정보 항목 삭제하기

myInfo = {
'이름':'Hong Gildong',
'나이':'30',
'연락처': '010-1234-5678',
'주민등록번호':'840315-1234567',
'주소':'대한민국 서울'
}
print('myInfo: {}'.format(myInfo))
deleteItems = ['연락처', '주민등록번호']
for item in deleteItems:
if item in myInfo:
del myInfo[item]
print('myInfo: {}'.format(myInfo))[출력 결과]
myInfo: {'이름': 'Hong Gildong', '나이': '30', '연락처': '010-1234-5678', '주민등록번호': '840315-1234567', '주소': '대한민국 서울'}
myInfo: {'이름': 'Hong Gildong', '나이': '30', '주소': '대한민국 서울'}
[나의 생각 정리]
오늘 인공지능 자격증 시험을 응시하면서 특정 값을 삭제하고 다른 값으로 대체하는 방식을 사용했다.
물론 pandas, sklearn 등 여러 공식 사이트를 참고해서 작성했지만
내가 원하는 대로 특정 column에 값을 0으로 바꾼다거나, ' '이런 공백인 데이터를 임의로 대체하는 방법들을
숙지하고 있으면 좋을 것 같다.
[적용점]
데이터 값 확인 및 변경
백준 코드 구현
“이 글은 제로베이스 데이터 스쿨 주 3일반 강의 자료 일부를 발췌하여 작성되었습니다.”