


[강의 요약]
[Part 03. 자료구조&알고리즘 with Python_ Ch 04. 알고리즘 문제풀이] 강의 수강
39_[연습문제] 최댓값 알고리즘(1)부터 50_[연습문제] 평균 알고리즘(2)까지 강의 수강하였음
🐢 100일 챌린지 🔥 : [▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰░ ] 51/100일 (51%)
[39_연습문제_최댓값 알고리즘(1)]
▶ 연습 문제 : 최댓값 알고리즘

▶ maxMod.py 최댓값 알고리즘 모듈
class MaxAlgorithm:
def __init__(self, ns):
self.nums = ns
self.maxNum = 0
self.maxNumCnt = 0
def setMaxNum(self):
self.maxNum = 0
for n in self.nums:
if self.maxNum < n:
self.maxNum = n
# 최댓값 계산
def getMaxNum(self):
self.setMaxNum()
return self.maxNum
def setMaxNumCnt(self):
self.setMaxNum()
for n in self.nums:
if self.maxNum == n:
self.maxNumCnt += 1
# 최댓값 개수 계산
def getMaxNumCnt(self):
self.setMaxNumCnt()
return self.maxNumCnt
▶ ex.py : 실행 코드
import random
import maxMod
if __name__ == '__main__':
nums = [random.randint(1, 50) for _ in range(30)]
print(f'nums:\n{nums}')
ma = maxMod.MaxAlgorithm(nums)
print(f'max num: {ma.getMaxNum()}')
print(f'max num cnt: {ma.getMaxNumCnt()}')1~50 사이의 중복 허용 난수 30개
[출력 결과]
nums:
[5, 12, 34, 50, 22, 45, 50, 9, 2, 16, 33, 27, 50, 1, 8, 17, 24, 13, 6, 30, 50, 40, 11, 43, 48, 26, 21, 50, 39, 50]
max num: 50
max num cnt: 6
[40_연습문제_최댓값 알고리즘(2)]
▶ 연습 문제 : 최댓값 알고리즘

▶ mod.py : 최댓값 알고리즘 모듈
# 리스트 평균값 반환
def getAvg(ns):
total = 0
for n in ns:
total += n
return total / len(ns)
# 최댓값 알고리즘으로 최대값 반환
def getMax(ns):
maxN = ns[0]
for n in ns:
if maxN < n:
maxN = n
return maxN
# 두 수의 차이의 절댓값을 소수 둘째 자리까지 반올림해 반환
def getDeviation(n1, n2):
return round(abs(n1 - n2), 2)
▶ ex.py : 실행 코드
import mod
scores = [100, 64, 94, 66, 75, 58, 99, 76, 96, 74,
54, 73, 88, 70, 68, 50, 95, 89, 69, 98]
score_avg = mod.getAvg(scores)
score_max = mod.getMax(scores)
deviation = mod.getDeviation(score_avg, score_max)
print(f'score_avg: {score_avg}')
print(f'score_max: {score_max}')
print(f'deviation: {deviation}')[출력 결과]
score_avg: 77.25
score_max: 100
deviation: 22.75
[41_연습문제_최솟값 알고리즘(1)]
▶ 연습 문제 : 최솟값 알고리즘

▶ minMod.py : 최솟값 알고리즘 모듈
class MinAlgorithm:
def __init__(self, ns):
self.nums = ns
self.minNum = 0
self.minNumCnt = 0
def setMinNum(self):
self.minNum = 51
for n in self.nums:
if self.minNum > n:
self.minNum = n
# 최솟값 계산
def getMinNum(self):
self.setMinNum()
return self.minNum
def setMinNumCnt(self):
self.setMinNum()
for n in self.nums:
if self.minNum == n:
self.minNumCnt += 1
# 최솟값의 개수를 계산
def getMinNumCnt(self):
self.setMinNumCnt()
return self.minNumCnt
▶ ex.py : 실행 코드
import random
import minMod
if __name__ == '__main__':
nums = []
for n in range(30):
nums.append(random.randint(1, 50))
print(f'nums:\n{nums}')
ma = minMod.MinAlgorithm(nums)
print(f'min num: {ma.getMinNum()}')
print(f'min num cnt: {ma.getMinNumCnt()}')1~50 사이 난수 30개 생성
[출력 결과]
nums:
[20, 5, 43, 26, 15, 44, 5, 8, 29, 50, 17, 38, 39, 23, 30, 14, 22, 41, 18, 5, 42, 37, 7, 16, 33, 24, 11, 21, 10, 19]
min num: 5
min num cnt: 3
[42_연습문제_최솟값 알고리즘(2)]
▶ 연습 문제 : 최솟값 알고리즘

▶ mod.py : 평균, 편차, 최솟값을 계산하는 함수
def getAvg(ns):
total = 0
for n in ns:
total += n
return total / len(ns)
def getMin(ns):
minN = ns[0]
for n in ns:
if minN > n:
minN = n
return minN
def getDeviation(n1, n2):
return round(abs(n1 - n2), 2)
# maxFlag=False일 때 최솟값을 반환
def getMaxOrMin(ns, maxFlag = True):
resultN = ns[0]
for n in ns:
if maxFlag:
if resultN < n:
resultN = n
else:
if resultN > n:
resultN = n
return resultN
▶ mod2.py : 클래스 기반 (평균, 편차, 최솟값을 계산하는 함수)
class ScoreManagement:
def __init__(self, ss):
self.scores = ss
self.score_tot = 0
self.score_avg = 0
self.score_min = 0
self.score_max = 0
def getMinScore(self):
if self.scores == None or len(self.scores) == 0:
return None
self.score_min = self.scores[0]
for score in self.scores:
if self.score_min > score:
self.score_min = score
return self.score_min
def getMaxScore(self):
if self.scores == None or len(self.scores) == 0:
return None
self.score_max = self.scores[0]
for score in self.scores:
if self.score_max < score:
self.score_max = score
return self.score_max
def getTotScore(self):
if self.scores == None or len(self.scores) == 0:
return None
self.score_tot = 0
for score in self.scores:
self.score_tot += score
return self.score_tot
def getAvgScore(self):
if self.scores == None or len(self.scores) == 0:
return None
self.score_avg = round(self.getTotScore() / len(self.scores), 2)
return self.score_avg
def getMaxDeviation(self):
result = abs(self.getAvgScore() - self.getMaxScore())
return round(result, 2)
def getMinDeviation(self):
result = abs(self.getAvgScore() - self.getMinScore())
return round(result, 2)객체지향적으로 처리
▶ ex.py : 실행 코드
import mod
scores = [100, 64, 94, 66, 75, 58, 99, 76, 96, 74,
54, 73, 88, 70, 68, 50, 95, 89, 69, 98]
scores_avg = mod.getAvg(scores)
scores_min = mod.getMaxOrMin(scores, maxFlag=False)
deviation = mod.getDeviation(scores_avg, scores_min)
print(f'scores_avg: {scores_avg}')
print(f'scores_min: {scores_min}')
print(f'deviation: {deviation}')
import mod2
sm = mod2.ScoreManagement(scores)
print(f'score_avg: {sm.getAvgScore()}')
print(f'score_min: {sm.getMinScore()}')
print(f'score_max: {sm.getMaxScore()}')
print(f'score_min_deviation: {sm.getMinDeviation()}')
print(f'score_max_deviation: {sm.getMaxDeviation()}')mod 함수 버전과 mod2 클래스 버전을 모두 테스트
[출력 결과]
scores_avg: 77.25
scores_min: 50
deviation: 27.25
score_avg: 77.25
score_min: 50
score_max: 100
score_min_deviation: 27.25
score_max_deviation: 22.75
[43_연습문제_최빈값 알고리즘(1)]
▶ 연습 문제 : 최빈값 알고리즘

▶ maxMod.py : 최빈값 알고리즘 모듈
class MaxAlgorithm:
def __init__(self, ns):
self.nums = ns
self.maxNum = 0
self.maxNumIdx = 0
def setMaxIdxAndNum(self):
self.maxNum = 0
self.maxNumIdx = 0
for i, n in enumerate(self.nums):
if self.maxNum < n:
self.maxNum = n
self.maxNumIdx = i
return self.maxNum
def getMaxNum(self):
return self.maxNum
def getMaxNumIdx(self):
return self.maxNumIdx리스트에서 최댓값과 그 인덱스를 함께 찾음
최빈값 알고리즘에서 빈도 배열의 최댓값을 구할 때 사용됨
▶ modeMod.py : 최빈값 알고리즘 모듈
import maxMod
class ModeAlgorithm:
def __init__(self, ns, mn):
self.nums = ns
self.maxNum = mn
self.indexes = []
def setIndexList(self):
self.indexes = [0 for i in range(self.maxNum + 1)]
for n in self.nums:
self.indexes[n] = self.indexes[n] + 1
def getIndexList(self):
if sum(self.indexes) == 0:
return None
else:
return self.indexes
def printAges(self):
n = 1
while True:
maxAlo = maxMod.MaxAlgorithm(self.indexes)
maxAlo.setMaxIdxAndNum()
maxNum = maxAlo.getMaxNum()
maxNumIdx = maxAlo.getMaxNumIdx()
if maxNum == 0:
break
print(f'[{n:0>3}] {maxNumIdx}세 빈도수: {maxNum}\t', end='')
print('+' * maxNum)
self.indexes[maxNumIdx] = 0
n += 1나이 빈도 리스트 생성
최빈값을 반복적으로 찾아내고, 해당 나이의 빈도만큼 + 출력
내림차순 빈도 그래프 출력
▶ ex.py : 실행 코드
import maxMod
import modeMod
ages = [25, 27, 27, 24, 31, 34, 33, 31, 29, 25,
45, 37, 38, 46, 47, 22, 24, 29, 33, 35,
27, 34, 37, 40, 42, 29, 27, 25, 26, 27,
31, 31, 32, 38, 25, 27, 28, 40, 41, 34]
print(f'employee cnt: {len(ages)}명')
maxAlg = maxMod.MaxAlgorithm(ages)
maxAlg.setMaxIdxAndNum()
maxAge = maxAlg.getMaxNum()
print(f'maxAge: {maxAge}세')
modAlg = modeMod.ModeAlgorithm(ages, maxAge)
modAlg.setIndexList()
print(f'IndexList: {modAlg.getIndexList()}')
modAlg.printAges()[출력 결과]

[44_연습문제_최빈값 알고리즘(2)]
▶ 연습 문제 : 최빈값 알고리즘

▶ mod.py : 로또 번호 최빈값 알고리즘 모듈
class LottoMode:
def __init__(self, ln):
self.lottoNums = ln
self.modeList = [0 for n in range(1, 47)]
# 각 번호별 등장 횟수를 저장
def getLottoNumMode(self):
for roundNums in self.lottoNums:
for num in roundNums:
self.modeList[num] = self.modeList[num] + 1
return self.modeList
# 각 번호의 빈도수만큼 * 출력
def printModeList(self):
if sum(self.modeList) == 0:
return None
for i, m in enumerate(self.modeList):
if i != 0:
print(f'번호: {i:>2}, 빈도: {m}, {"*" * m}')
▶ ex.py : 실행 코드
import mod
lottoNums = [[13, 23, 15, 5, 6, 39], [36, 13, 5, 3, 30, 16], [43, 1, 15, 9, 3, 38],
...
[20, 23, 6, 2, 34, 44]]
lm = mod.LottoMode(lottoNums)
mList = lm.getLottoNumMode()
# print(f'mList: {mList}')
lm.printModeList()전체 번호(1~45)에 대한 출현 횟수를 *로 출력
[출력 결과]
번호: 1, 빈도: 3, ***
번호: 2, 빈도: 3, ***
번호: 3, 빈도: 7, *******
번호: 4, 빈도: 6, ******
...
번호: 45, 빈도: 5, *****
[45_연습문제_근삿값 알고리즘(1)]
▶ 연습 문제 : 근삿값 알고리즘

▶ nearMod.py : 근삿값 알고리즘 모듈
class NearAlgorithm:
def __init__(self, d):
self.temps = {0:24, 5:22, 10:20, 15:16, 20:13, 25:10, 30:6}
self.depth = d
self.nearNum = 0
self.minNum = 24
def getNearNumber(self):
for n in self.temps.keys():
absNum = abs(n - self.depth)
if absNum < self.minNum:
self.minNum = absNum
self.nearNum = n
return self.temps[self.nearNum]입력 수심과 기존 수심 키 간의 차이를 계산해
가장 가까운 수심에 해당하는 수온을 반환
▶ ex.py : 실행 코드
import nearMod
depth = int(float(input('input depth: ')))
print(f'depth: {depth}m')
na = nearMod.NearAlgorithm(depth)
temp = na.getNearNumber()
print(f'water temperature: {temp}도')[출력 결과]
input depth: 12.8
depth: 12m
water temperature: 20도사용자가 12.8m를 입력하면 근사 수심 10m의 수온 20도가 출력됨
[46_연습문제_근삿값 알고리즘(2)]
▶ 연습 문제 : 근삿값 알고리즘

▶ nearMod.py : BMI 판정용 근삿값 알고리즘 모듈
class BmiAlgorithm:
def __init__(self, w, h):
self.BMISection = {18.5:['저체중', '정상'],
23:['정상','과체중'],
25:['과체중', '비만']}
self.userWeight = w
self.userHeight = h
self.userBMI = 0
self.userCondition = ''
self.nearNum = 0
self.minNum = 25
def calculatorBMI(self):
self.userBMI = round(self.userWeight / (self.userHeight * self.userHeight), 2)
print(f'userBMI: {self.userBMI}')
def printUserCondition(self):
for n in self.BMISection.keys():
absNum = abs(n - self.userBMI)
if absNum < self.minNum:
self.minNum = absNum
self.nearNum = n
print(f'self.nearNum: {self.nearNum}')
if self.userBMI <= self.nearNum:
self.userCondition = self.BMISection[self.nearNum][0]
else:
self.userCondition = self.BMISection[self.nearNum][1]
print(f'self.userCondition: {self.userCondition}')BMI 수치를 기준표(BMISection)와 비교해 가장 가까운 값 판단
userBMI가 기준 이하이면 전자, 이상이면 후자의 신체상태로 분류
▶ ex.py : 실행 코드
import nearMod
uWeight = float(input('input weight(Kg): '))
uHeight = float(input('input height(m): '))
na = nearMod.BmiAlgorithm(uWeight, uHeight)
na.calculatorBMI()
na.printUserCondition()[출력 결과]
input weight(Kg): 60
input height(m): 1.68
userBMI: 21.26
self.nearNum: 23
self.userCondition: 정상BMI = 60 ÷ (1.68²) ≈ 21.26 → 기준점 23과 가장 가까움 → 정상 판정
[47_연습문제_재귀 알고리즘(1)]
▶ 연습 문제 : 재귀 알고리즘

▶ ex.py : 재귀 알고리즘 기반 매출 증감 분석 코드
sales = [12000, 13000, 12500, 11000, 10500, 98000, 91000, 91500, 10500, 11500, 12000, 12500]
def salesUpAndDown(ss):
if len(ss) == 1:
return ss
print(f'sales: {ss}')
currentSales = ss.pop(0)
nextSales = ss[0]
increase = nextSales - currentSales
if increase > 0:
increase = '+' + str(increase)
print(f'매출 증감액: {increase}')
return salesUpAndDown(ss)
if __name__ == '__main__':
salesUpAndDown(sales)리스트의 첫 번째와 두 번째 값을 비교해 증감액 계산
리스트를 점점 줄여가며 재귀적으로 전체 구간을 출력
증가는 +, 감소는 그냥 음수로 표시됨
[출력 결과]
sales: [12000, 13000, 12500, 11000, 10500, 98000, 91000, 91500, 10500, 11500, 12000, 12500]
매출 증감액: +1000
sales: [13000, 12500, 11000, 10500, 98000, 91000, 91500, 10500, 11500, 12000, 12500]
매출 증감액: -500
sales: [12500, 11000, 10500, 98000, 91000, 91500, 10500, 11500, 12000, 12500]
매출 증감액: -1500
...
sales: [12000, 12500]
매출 증감액: +500
[48_연습문제_재귀 알고리즘(2)]
▶ 연습 문제 : 재귀 알고리즘

▶ mod.py : 정수 구간 합 재귀 알고리즘 모듈
class NumsSum:
def __init__(self, n1, n2):
self.bigNum = 0
self.smallNum = 0
self.setN1N2(n1, n2)
def setN1N2(self, n1, n2):
self.bigNum = n1
self.smallNum = n2
if n1 < n2:
self.bigNum = n2
self.smallNum = n1
# 1부터 n까지의 합을 재귀적으로 계산
def addNum(self, n):
if n <= 1:
return n
return n + self.addNum(n - 1)
# 전체 합에서 앞부분 합을 빼는 방식으로 두 수 사이의 정수 합만 도출
def sumBetweenNums(self):
return self.addNum(self.bigNum - 1) - self.addNum(self.smallNum)
▶ ex.py : 실행 코드
import mod
num1 = int(input(f'input number1: '))
num2 = int(input(f'input number2: '))
ns = mod.NumsSum(num1, num2)
result = ns.sumBetweenNums()
print(f'result: {result}')[출력 결과]
input number1: 4
input number2: 9
result: 39
[49_연습문제_평균 알고리즘(1)]
▶ 연습 문제 : 평균 알고리즘

▶ maxAlgorithm.py : 최댓값 제거 알고리즘 모듈
class MaxAlgorithm:
def __init__(self, ss):
self.scores = ss
self.maxScore = 0
self.maxIdx = 0
def removeMaxScore(self):
self.maxScore = self.scores[0]
for i, s in enumerate(self.scores):
if self.maxScore < s:
self.maxScore = s
self.maxIdx = i
print(f'self.maxScore: {self.maxScore}')
print(f'self.maxIdx: {self.maxIdx}')
self.scores.pop(self.maxIdx)
print(f'scores: {self.scores}')리스트 내 최댓값을 탐색 후 삭제
▶ ex.py : 실행 코드
class Top5Players:
def __init__(self, cts, ns):
self.currentScores = cts
self.newScore = ns
def setAlignScore(self):
nearIdx = 0
minNum = 10.0
for i, s in enumerate(self.currentScores):
absNum = abs(self.newScore - s)
if absNum < minNum:
minNum = absNum
nearIdx = i
if self.newScore >= self.currentScores[nearIdx]:
for i in range(len(self.currentScores)-1, nearIdx, -1):
self.currentScores[i] = self.currentScores[i-1]
self.currentScores[nearIdx] = self.newScore
else:
for i in range(len(self.currentScores)-1, nearIdx+1, -1):
self.currentScores[i] = self.currentScores[i-1]
self.currentScores[nearIdx+1] = self.newScore
def getFinalTop5Scroes(self):
return self.currentScores점수 리스트에서 최댓값과 최솟값 제거
평균 계산 후 기존 순위에 삽입
최종 top5 순위 리스트 출력
[출력 결과]
scores: [6.7, 5.9, 8.1, 7.9, 6.7, 7.3, 7.2, 8.2, 6.2, 5.8]
self.maxScore: 8.2
self.maxIdx: 7
scores: [6.7, 5.9, 8.1, 7.9, 6.7, 7.3, 7.2, 6.2, 5.8]
self.minScore: 5.8
self.minIdx: 8
scores: [6.7, 5.9, 8.1, 7.9, 6.7, 7.3, 7.2, 6.2]
total: 56.0
average: 7.0
top5Scores: [9.12, 8.95, 8.12, 7.0, 6.9]
[50_연습문제_평균 알고리즘(2)]
▶ 연습 문제 : 평균 알고리즘
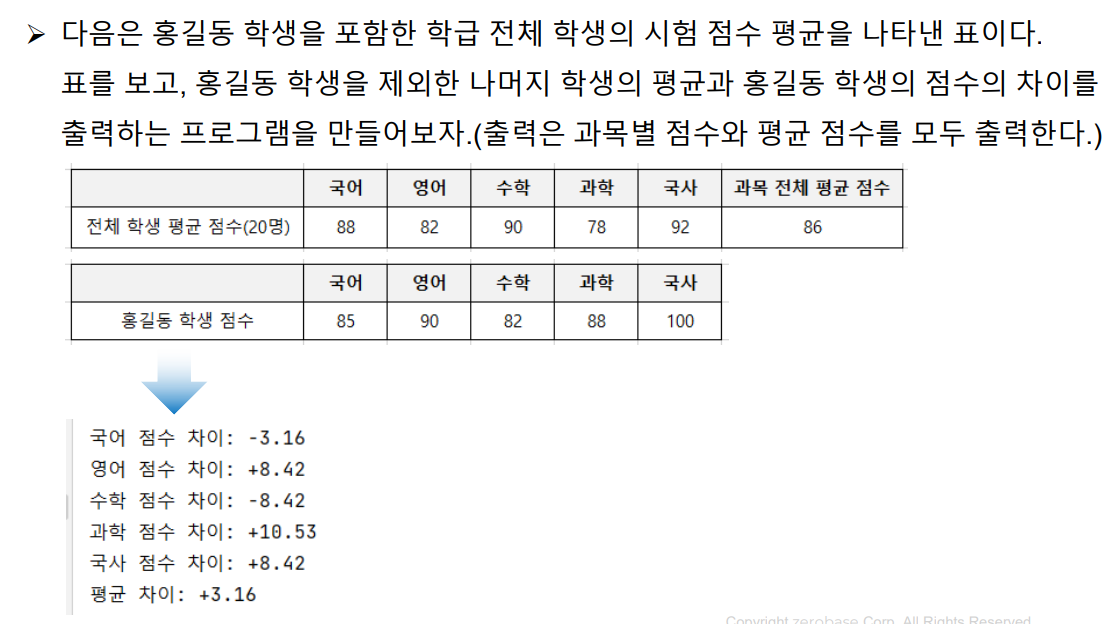
▶ ex.py : 홍길동 학생과 나머지 학생 평균 비교 코드
kor_avg = 88; eng_avg = 82; mat_avg = 90
sci_avg = 78; his_avg = 92
hong_kor_score = 85; hong_eng_score = 90; hong_mat_score = 82
hong_sci_score = 88; hong_his_score = 100
stu19cnt_kor_total = kor_avg * 20 - hong_kor_score
stu19cnt_eng_total = eng_avg * 20 - hong_eng_score
stu19cnt_mat_total = mat_avg * 20 - hong_mat_score
stu19cnt_sci_total = sci_avg * 20 - hong_sci_score
stu19cnt_his_total = his_avg * 20 - hong_his_score
stu19cnt_kor_avg = stu19cnt_kor_total / 19
stu19cnt_eng_avg = stu19cnt_eng_total / 19
stu19cnt_mat_avg = stu19cnt_mat_total / 19
stu19cnt_sci_avg = stu19cnt_sci_total / 19
stu19cnt_his_avg = stu19cnt_his_total / 19
kor_gap = hong_kor_score - stu19cnt_kor_avg
eng_gap = hong_eng_score - stu19cnt_eng_avg
mat_gap = hong_mat_score - stu19cnt_mat_avg
sci_gap = hong_sci_score - stu19cnt_sci_avg
his_gap = hong_his_score - stu19cnt_his_avg
print(f'국어 점수 차이: {"+" + str(round(kor_gap, 2)) if kor_gap > 0 else round(kor_gap, 2)}')
print(f'영어 점수 차이: {"+" + str(round(eng_gap, 2)) if eng_gap > 0 else round(eng_gap, 2)}')
print(f'수학 점수 차이: {"+" + str(round(mat_gap, 2)) if mat_gap > 0 else round(mat_gap, 2)}')
print(f'과학 점수 차이: {"+" + str(round(sci_gap, 2)) if sci_gap > 0 else round(sci_gap, 2)}')
print(f'국사 점수 차이: {"+" + str(round(his_gap, 2)) if his_gap > 0 else round(his_gap, 2)}')
stu19Cnt_total = stu19cnt_kor_avg + stu19cnt_eng_avg + stu19cnt_mat_avg + stu19cnt_sci_avg + stu19cnt_his_avg
stu19Cnt_avg = stu19Cnt_total / 5
hong_total = hong_kor_score + hong_eng_score + hong_mat_score + hong_sci_score + hong_his_score
hong_avg = hong_total / 5
avg_gap = round(hong_avg - stu19Cnt_avg, 2)
print(f'평균 차이: {"+" + str(round(avg_gap, 2)) if avg_gap > 0 else round(avg_gap, 2)}')전체 평균 × 20 - 홍길동 점수 → 19명 총합 계산
19명 평균 계산 → 홍길동과 과목별/전체 평균 차이 출력
[출력 결과]
국어 점수 차이: -3.21
영어 점수 차이: +7.47
수학 점수 차이: -7.58
과학 점수 차이: +8.95
국사 점수 차이: +7.0
평균 차이: +2.13
[나의 생각 정리]
이론으로 배운 내용을 연습문제를 풀면서 복습할 수 있었다.
각 알고리즘의 특징을 정리할 수 있었다.
[적용점]
알고리즘을 요구하는 코딩 테스트 문제 풀 때 사용
알고리즘 관련 면접 질문 대비
“이 글은 제로베이스 데이터 스쿨 주 3일반 강의 자료 일부를 발췌하여 작성되었습니다.”
'제로베이스 데이터 취업 파트타임 > 100일 챌린지_일일 학습 일지' 카테고리의 다른 글
| 제로베이스 데이터 파트타임 스쿨 학습 일지 [25.05.08] (1) | 2025.05.08 |
|---|---|
| 제로베이스 데이터 파트타임 스쿨 학습 일지 [25.05.07] (0) | 2025.05.07 |
| 제로베이스 데이터 파트타임 스쿨 학습 일지 [25.05.05] (1) | 2025.05.05 |
| 제로베이스 데이터 파트타임 스쿨 학습 일지 [25.05.04] (2) | 2025.05.04 |
| 제로베이스 데이터 파트타임 스쿨 학습 일지 [25.05.03] (0) | 2025.05.03 |