


[강의 요약]
[Part 04. EDA/웹 크롤링/파이썬 프로그래밍_ Ch 01~02] 강의 수강
Ch 01전체, Ch02_클립 03까지 강의 수강하였음
🐢 100일 챌린지 🔥 : [▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰▰ ] 52/100일 (52%)서울시 CCTV 현황 데이터 분석 강의 수강을 시작했다.
데이터는 이곳에서 얻을 수 있다. (서울시 자치구 년도별 CCTV 설치 현황)
예전에 팀으로 대회 나갔을 때 서울시 공공데이터 많이 사용했는데... 그땐 아무것도 못하는 초보였다 ㅠ
그리고 서울 구별 인구 통계 데이터도 사용하는데, 강의가 옛날에 만들어져서 그런지
현재의 공공데이터와 차이가 있을 수 있다.
그래도 참고할 사람은 여길 참고
여기서도 예전에 공공데이터랑 open API를 발급해서 뭘 한 적이 있다.
[Ch 01. 오리엔테이션]
Ch 01의 내용은 말 그대로 오리엔테이션이었다.
conda 환경설정이나 주피터 노트북이나 vscode 사용법 등
아 matplotlib 한글 설정도 다뤘는데 이건 해봤어서 pass
굳이 학습 일지에 작성할 내용들은 아니어서 넘어가겠다.
진짜 잘 정리하고 공부해야 하는 부분은 Chapter 02. 서울시 CCTV 현황 데이터 분석이다.
[Ch 02. 01_이론]
▶ 서울시 CCTV 현황 분석 프로젝트 소개 및 데이터 출처
위에서 말한 대로 강의자료와 현재 온라인에 올라와있는 공공데이터는 싱크가 맞지 않을 수 있다.
현시점으로 새로운 프로젝트를 만든다면 현재 올라온 데이터를 사용하는 게 맞지만
지금은 학습을 목적으로 강의를 수강하고 공부하는 것이기 때문에
강의에서 제공하는 데이터를 사용할 예정이다.
우선 강의 목표는 다음과 같다.

어느 정도 할 줄은 알지만, 백지상태에서 해보라고 한다면...
버벅거리면서 정말 기본적인 코드만 작성할 수 있다.
그러니까 공부해야겠지?
[Ch 02. 02_이론]
▶ 서울시 CCTV 현황 분석 데이터 읽기
보통 데이터를 분석할 때 pandas를 사용해서 데이터를 불러온다.
강의자료에서는 설명하는 pandas 특징은 다음과 같다.
- Python에서 R만큼의 강력한 데이터 핸들링 성능을 제공하는 모듈
- 단일 프로세스에서는 최대 효율
- 코딩 가능하고 응용 가능한 엑셀로 받아들여도 됨 (공감한다)
- 누군가는 스테로이드를 맞은 엑셀로 표현함 (이것도 무슨 의미인지 알 것 같다 ㅋㅋ)
아무튼, 내가 느끼기에는 pandas는 파이썬에서 데이터 분석을 쉽게 할 수 있도록 도와주는 라이브러리이고
엑셀처럼 표 형태의 데이터(테이블)를 다룰 수 있게 해 주고 데이터 불러오기, 정리, 필터링, 통계 분석 등에 유용했다.
서울시 CCTV 현황 분석 데이터는 csv파일과 엑셀 파일이 있으므로
둘 다 pandas를 이용해 데이터를 불러와보자
import pandas as pd먼저 import 명령으로 사용하겠다고 선언하는데, 사용방법이 있다.
- importMODULE
- MODULE을 사용하겠다
- 사용 : MODULE.function
- importMODULEasmd
- MODULE을 사용할 건데, 앞으로는md라는 이름으로 부르겠다
- 사용 : md.function
- fromMODULEimportfunction
- MODULE에 포함된 function이라는 함수만 사용하겠다
- 사용 : function
그러면 위에 있는 코드는 pandas를 사용할건데, 앞으로는 pd라는 이름으로 부리겠다.라는 의미다.
CCTV_Seoul = pd.read_csv("./data/01. Seoul_CCTV.csv", encoding="utf-8")
CCTV_Seoul.head()이미 파일이 UTF-8로 저장되어 있으면 encoding="utf-8"을 명시하지 않아도 괜찮다.
하지만 한글 csv 파일은 명시적으로 encoding 지정하는 게 좋다.
참고로 .head()는 pandas의 DataFrame에서 상위 n개의 행을 미리 보기로 출력하는 함수다.
기본값은 5여서 아무것도 작성하지 않으면 5개의 행만 보여준다.
사용하는 이유는 파일이 잘 불러졌는지 확인하기 위해서!
[코드 실행 결과]


그리고 이건 위에서 .head()로 확인한 데이터프레임의 5개의 행을 어떻게 보는지 설명한 사진이다.
엑셀처럼 행과 열로 구성된 2차원 표 구조인데
Index는 행 번호. 각 행(row)의 고유 번호고 0부터 시작한다.
Column Name은 열 이름인데, 각 열의 제목이다.
데이터의 종류나 항목을 나타내고, 고유한 이름으로 접근이 가능하다.
Values는 말 그대로 값인데, 실제 데이터가 들어있는 셀들의 내용이다.
숫자, 문자, 날짜 등 다양한 형식이 가능하다.
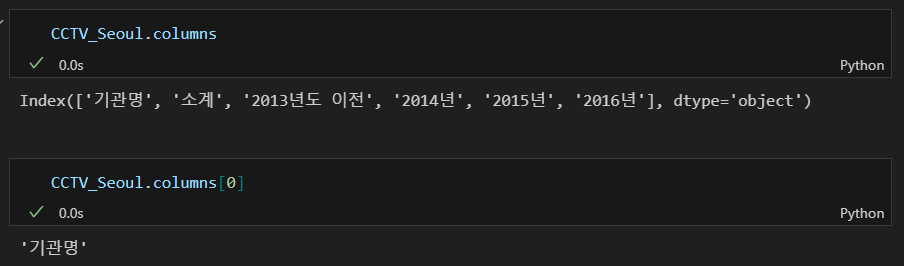
column의 이름을 조회한 코드와 출력 결과인데, 기본 사용 방법은 다음과 같다.
df.columns : 모든 열의 이름을 확인
df.columns[0] : 첫 번째 열의 이름만 가져오기
그러면 칼럼 이름을 바꾸고 싶으면 어떻게 해야 할까?
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0]: "구별"}, inplace=True)
CCTV_Seoul.head()
첫 번째 칼럼 이름 '기관명'을 가져와서
딕셔너리 형식으로 "이전이름: 새이름" 설정을 한다.
그러면 '기관명'이 "구별"로 칼럼명이 변경된다. 출력결과에서도 확인 가능하다.
참고로 inplace = True는 원본 DataFrame을 직접 수정한다는 의미다.
+ 다른 열들도 바꾸고 싶으면 columns={'기존1': '새이름1', '기존2': '새이름2'} 이렇게 가능하다.
그리고 아까 위에서 말했던 엑셀 파일도 pandas로 열어보자.
(tmi. 나는 로컬에서 vscode로 코드를 실행중이여서, 아래 코드 실행할 때 에러가 떴다)


보면 바로 위에서 csv파일을 read한 것과 다르게 보기 복잡한 형태다.
엑셀에서는 보기좋게 셀 병합이 되어있지만
pandas에서는 셀 병합 기능이 없기때문에 풀어져서 보인다.
그래서 보기 좋게 하기위해 다른 코드로 불러야한다.
[나의 생각 정리]
데이터 분석을 공부하고 싶었는데 마침 해당 강의 수강 순서여서 좋았다.
기초적인 데이터 분석 방법을 복습하는 좋은 기회라 생각한다.
[적용점]
데이터 분석(EDA)
“이 글은 제로베이스 데이터 스쿨 주 3일반 강의 자료 일부를 발췌하여 작성되었습니다.”
'제로베이스 데이터 취업 파트타임 > 100일 챌린지_일일 학습 일지' 카테고리의 다른 글
| 제로베이스 데이터 파트타임 스쿨 학습 일지 [25.05.09] (0) | 2025.05.09 |
|---|---|
| 제로베이스 데이터 파트타임 스쿨 학습 일지 [25.05.08] (1) | 2025.05.08 |
| 제로베이스 데이터 파트타임 스쿨 학습 일지 [25.05.06] (0) | 2025.05.06 |
| 제로베이스 데이터 파트타임 스쿨 학습 일지 [25.05.05] (1) | 2025.05.05 |
| 제로베이스 데이터 파트타임 스쿨 학습 일지 [25.05.04] (2) | 2025.05.04 |